04.30.2006 21:39
doctest chaining and python module template
I just realized (am I am sure this is
documented) that within a doc string, that doctest chain beyond
just the current group. I thought before (which was not correct)
that everything was reset after the first result. This makes my
life easier for setting up more complicated examples. I was worried
that I would have to keep generating longer and longer blocks. For
example, these work:
'''
Some silly math
>>> a = 1
>>> print a
1
>>> print a+1
2
And...
>>> print a+2
3
'''
Here is my current template file for a module. Note that this is a
work in progress! Being that these are just templates and they need
to be improved, I give permission for folks to use these how ever
they see fit.
#!/usr/bin/env python __version__ = '$Revision: 2054 $'.split()[1] __date__ = '$Date: 2006-04-27 23:32:12 -0400 (Thu, 27 Apr 2006) $'.split()[1] __author__ = 'Kurt Schwehr'And verbosity looks something like this:
__doc__=''' Describe the module here.
Example file to start with. Make sure to do these::
chmod +x mynewfile.py svn add mynewfile.py svn propedit svn:keywords mynewfile.py Revision Date svn commit mynewfile.py
A doctest looks like this
>>> print 2 2
@see: Where else to look
@author: '''+__author__+''' @version: ''' + __version__ +''' @copyright: 2006
@var __date__: Date of last svn commit
@bug: Write this module @todo: Design this module @todo: Write doctests @todo: Write a corresponding unittest file in the test directory
@undocumented: __version__ __author__ __doc__ myparser '''
# python standard libraries import sys, os
# External modules
# Local modules import verbosity from verbosity import BOMBASTIC,VERBOSE,TRACE,TERSE,ALWAYS
######################################################################
# FIX: write the module here
class MyClass ''' FIX: describe the class here
@todo: design MyClass @todo: code MyClass ''' def __init__(self,myparam): '''Create a MyModule object @param myparam: some arg @type myparam: bool ''' assert False # FIX: implement this
def getSomething(self,somearg): ''' Fetch some value based on somearg @return: a something based on somearg @rtype: int ''' assert False # FIX: implement this
######################################################################
if __name__=='__main__': from optparse import OptionParser myparser = OptionParser(usage="%prog [options]", version="%prog "+__version__) myparser.add_option('--test','--doc-test',dest='doctest',
default=False,action='store_true', help='run the documentation tests') verbosity.addVerbosityOptions(myparser) (options,args) = myparser.parse_args() if options.doctest: import os; print os.path.basename(sys.argv[0]), 'doctests ...', sys.argv= [sys.argv[0]] if options.verbosity>=VERBOSE: sys.argv.append('-v') import doctest numfail,numtests=doctest.testmod() if numfail==0: print 'ok' else: print 'FAILED'
#!/usr/bin/env python
__version__ = '$Revision: 2054 $'.split()[1] # See man ident __date__ = '$Date: 2006-04-27 23:32:12 -0400 (Thu, 27 Apr 2006) $'.split()[1] __author__ = 'Kurt Schwehr' __doc__=''' @author: '''+__author__+''' @version: ''' + __version__ +''' @copyright: Copyright (C) 2005 Kurt Schwehr @var __date__: Date of last svn commit @undocumented: __version__ __author__ __doc__ myparser
@todo: make a print function that knows about verbosity ''' import sys
BOMBASTIC= 4 VERBOSE = 3 TRACE = 2 TERSE = 1 ALWAYS = 0 NEVER = 0 # Confusing, eh? # Pass in 0 for NEVER from the user side
# def addVerbosityOptions(parser): """ Added the verbosity options to a parser """ parser.add_option('-v','--verbose',action="count",dest='verbosity',default=0, help='how much information to give. Specify multiple times to increase verbosity') parser.add_option('--verbosity',dest='verbosity',type='int', help='Specify verbosity. Should be in the range of ' +str(ALWAYS)+'...'+str(BOMBASTIC)+' (None...Bombastic)') parser.add_option('--noisy',dest='verbosity', action='store_const', const=2*BOMBASTIC, help='Go for the max verbosity ['+str(2*BOMBASTIC)+']')
# FIX: what to do for a main? Perhaps run a test?
######################################################################
if __name__=='__main__': from optparse import OptionParser myparser = OptionParser(usage="%prog [options]", version="%prog "+__version__) myparser.add_option('--test','--doc-test',dest='doctest',default=False,action='store_true', help='run the documentation tests') addVerbosityOptions(myparser) (options,args) = myparser.parse_args() if options.doctest: import os; print os.path.basename(sys.argv[0]),'doctests ...', sys.argv= [sys.argv[0]] if options.verbosity>=VERBOSE: sys.argv.append('-v') import doctest numfail,numtests=doctest.testmod() if numfail==0: print 'ok' else: print 'FAILED'
04.30.2006 21:09
Analogy for ship navigation
When driving a ship, it is important
to keep your eyes out the window. This is just like what is
happening with drivers using the in-car GPS systems. If you don't
look at what is coming up, you may really regret it.
UK drivers trust GPS more than their own eyes [engadget]
This is about the 5th time I have seen this story this week, but I had to bring up the relation to the Chart-Of-The-Future. Driving only by instruments is sometimes forced on a pilot, but never recommended.
UK drivers trust GPS more than their own eyes [engadget]
This is about the 5th time I have seen this story this week, but I had to bring up the relation to the Chart-Of-The-Future. Driving only by instruments is sometimes forced on a pilot, but never recommended.
We've heard reports before about the dangers of driving while under the influence of GPS, but it looks like drivers in the UK have taken trust of their navigation units to the extreme. Twice in the space of the last two weeks, we've seen reports of British drivers taking serious risks because they trust the info displayed on the small screen more than what they see through their windshield. In the most recent case, drivers passing through the village of Luckington have found themselves landing in the River Avon, by following a GPS-recommended route that pointed to a bridge that has been closed for a week. ...
04.30.2006 06:12
geocoder.us
http://geocoder.us/
If you live in Canada, you can use http://geocoder.ca to get the exact longitude and latitude of your position.
If you live in Europe, you can use http://www.maporama.com to get the exact longitude and latitude of your position.
If you live in Canada, you can use http://geocoder.ca to get the exact longitude and latitude of your position.
If you live in Europe, you can use http://www.maporama.com to get the exact longitude and latitude of your position.
04.29.2006 14:20
build your own web server with python
I want to add a webserver to one of
my programs so that I can allow people to view a web page that
presents the latest statistics collected by the logger. This way, I
can connect to a remote data logger and see how it has been doing.
This is about the simplest web server that can be done, but all it
does is let someone walk the files in the tree below to working
directory of the server program.
That is fine, but does not let me generate my own web pages. I want to present the status for what is happening within a small program. I got this idea from what Roland is doing with GeoZui4D.
#!/usr/bin/env python
import BaseHTTPServer, SimpleHTTPServer
server = BaseHTTPServer.HTTPServer(('',8080),SimpleHTTPServer.SimpleHTTPRequestHandler)
server.serve_forever()
If I then do an "open http://localhost:8080/" here is what I see...
Directory listing for /
That is fine, but does not let me generate my own web pages. I want to present the status for what is happening within a small program. I got this idea from what Roland is doing with GeoZui4D.
#!/usr/bin/env python
import BaseHTTPServer
#
class httpHandler(BaseHTTPServer.BaseHTTPRequestHandler):
def do_GET(self):
msg = 'hello'
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length",len(msg))
self.end_headers()
self.wfile.write(msg)
#
if __name__=='__main__':
server = BaseHTTPServer.HTTPServer(('',8080),httpHandler)
server.serve_forever()
Now all I need to do is dip into the application's data structures
to see what is going on. Time for me to try out a multithreaded
python application next. Will python threads utilize multiple CPUs?
That would be really nice.04.29.2006 13:11
Portsmouth port security
Port
director praises new rules [sea coast online]
PORTSMOUTH - Director of Ports and Harbors Geno Marconi said the port of New Hampshire is safe.
The Bush Administration's new regulations that require background checks for all port workers to uncover links to terrorism and verify all workers are legal U.S. residents will only help to make it safer, Marconi said Friday. ...
04.29.2006 07:52
GeoZui4D XPath example
I am sold on the power of XPath for
dealing with XML data. XPath makes it much more manageable to cope
with complex data structures in ML files. The ease of searching
with XPath is impressive. Here is my first real example of trying
to do something useful with XPath. First, here is an example from
GeoZui4D. This is an example of a gzx file that contains the
location of two ships at a couple time stamps. Actually, I chopped
up an example file with one ship to make a more interesting
example.
<?xml version="1.0" encoding="ISO-8859-1"?>
<GZ>
<Object type="Boat" label="boat1" path="on" bow_size="1.0 15.0 10.0"
hull_size="13.7 35.0 13.0" bridge_nudge="18.0"
stern_size="12.0 15.0 11.0" bridge_size="13.0 14.0 18.0"
local_origin="468275.0 4595425.6 0.0">
<Position position="468082.0 4595833.5 0.0" time="1089386678.0"></Position>
<Position position="468069.5 4596129.7 0.0" time="1089386836.0"></Position>
<Position position="467903.1 4596241.4 0.0" time="1089386941.0"></Position>
</Object>
<Object type="Boat" label="ship2">
<Position position="466388.8 4599560.5 0.0" time="1089394391.0"></Position>
<Position position="466402.3 4599486.4 0.0" time="1089394516.0"></Position>
</Object>
</GZ>
Now, what if I want to get either the first or last value for a
particular vessel? Here is all I have to do:
#!/usr/bin/env python
import lxml.etree
#
boats = lxml.etree.parse('example.xml')
#
lastpos1=boats.xpath('//GZ/Object[@label="boat1"]/Position[last()]')
print len(lastpos1), lastpos1[0].attrib
#
firstpos2=boats.xpath('//GZ/Object[@label="ship2"]/Position[1]')
print len(firstpos2),firstpos2[0].attrib
Running the above program returns this:
1 {'position': '467903.1 4596241.4 0.0', 'time': '1089386941.0'}
1 {'position': '466388.8 4599560.5 0.0', 'time': '1089394391.0'}
Where did I learn how to do this? http://www.zvon.org/xxl/XPathTutorial/General/examples.html
- check out example 5.04.29.2006 06:34
Small Linux systems
World's
smallest networked Linux computer? [linuxdevices.com]...
Intec Automation is shipping a tiny ColdFire-powered CPU module claimed to be the smallest Linux SBC (single-board computer) with Internet connectivity, a reasonable amount of memory, and "massive control functionality." The WildFireMod measures 1.9 x 1.7 inches (49 x 44mm), and targets data acquisition systems, communications, electric and internal combustion motor controllers, robotics, automotive, avionics, and industrial control. ...
04.29.2006 06:30
OpenVPN
http://openvpn.net/ loots like it might
be an interesting solution to the UNH world of VPN trouble. At UNH,
Windows VPN clients are free, but I have to pay for a Mac Client
and I haven't even looked to see what they say about Linux.
04.29.2006 06:19
NASA World Wind database discussion
Not as much discussion as i had
hoped, but it is a quick read...
http://radar.oreilly.com/archives/2006/04/database_war_stories_4_nasa_wo.html - Database War Stories #4: NASA World Wind
http://radar.oreilly.com/archives/2006/04/database_war_stories_4_nasa_wo.html - Database War Stories #4: NASA World Wind
04.28.2006 07:51
lxml and xpath
I spent about 2 hours yesterday at
NOAA talking to Jack who is one of the pydro developers. Pydro is a
very large python application that does all sorts of neat things
with python. He overloaded my brain with all kinds of ideas, but an
easiest one for me to use is XPath.
He codes under the Microsoft DOM, so I can't use that. I found out this morning that elementtree only implements a small subset of XPath. That is when I discovered lxml. lxml wraps libxml2 with an ElementTree interface, but then extends that to provide more capabilities. First, I created a lxml-py.info
Now for an example. This first example shows how to load in an xml string via the string interface. This makes is easy to embed the xml document inside of a python file. I should really do this for the current application that I am working on so that I don't have to keep shoving around the path to the core xml specification file.
He codes under the Microsoft DOM, so I can't use that. I found out this morning that elementtree only implements a small subset of XPath. That is when I discovered lxml. lxml wraps libxml2 with an ElementTree interface, but then extends that to provide more capabilities. First, I created a lxml-py.info
Now for an example. This first example shows how to load in an xml string via the string interface. This makes is easy to embed the xml document inside of a python file. I should really do this for the current application that I am working on so that I don't have to keep shoving around the path to the core xml specification file.
#!/usr/bin/env python
from StringIO import StringIO
import lxml.etree
f=StringIO('<foo><bar>some text</bar></foo>')
doc = lxml.etree.parse(f)
r = doc.xpath('/foo/bar')
print 'length of result should be 1: ',len(r)
print r[0].tag
print r[0].text
Here is what the code prints when run:
length of result should be 1: 1 bar some text
04.28.2006 07:03
mullesight still not happening
Mullesight is still not working for
me. I tried this with no possitive results... First I did an hfstar
of /Applications/MulleSight-1.0.9 and untared it on the machine
with the iSight (running 10.4.6). Then I grabbed
grabframes-0.2.bash from http://schwehr.org/software/scripts/.
After a chmod +x graframes-0.2.bash, I ran the script, but got this
error:
/Applications/MulleSight-1.0.9/MulleSightAsWebcam.applescript:811:845:
execution error: No user interaction allowed. (-1713)
Bummer.04.28.2006 05:38
Google sketchup
Or was that ketchup?
http://sketchup.google.com/download.html:
http://sketchup.google.com/download.html:
Download Google SketchUp (free) Windows: Version # 5.0.245 Macintosh: Coming Soon
04.26.2006 17:30
Mullesight web cam
I am trying to get a web camera going
with my old Mullesight time lapse frame grabs but for some reason
it is not grabbing frames with Mullesight 1.0.10 and Mac OSX
10.4.6. Not sure what is wrong 
04.24.2006 23:14
small ais transmitter
Here is a little unit for Class B AIS
(?is that right?) that does limited transmission: http://maritec.co.za/index.php?pr=APIRB
APIRB is a low cost AIS transmit only device, designed to operate in
conformance with ITU-R M.1371-1.
...
APIRB allows vessels not required to fit Class A in terms of SOLAS
regulation, to fit an AIS device that meets ISPS code and Marine
Domain Awareness (MDA) requirements, where applicable. It is also a
solution for Search and Rescue craft that only need to transmit their
own identification and position.
APIRB supports AIS VDL messages 18, 24A and 24B
...
04.24.2006 08:07
ElementTree colorizer
I need to look at
http://effbot.python-hosting.com/browser/stuff/sandbox/pythondoc/
which is a python source colorizer and something for
elementtrees.
04.23.2006 17:12
Agile Manifesto
Brian L. saw a copy of Agile developement
using the ICONIX process that I got from ESRI and asked me if I
had read the Agile
Manifesto. Not sure why I should want to sign it, but the
principles do sound appealing.
I took two classes in 1997 from UCSC extension that were aimed at getting us to use UML. I'm still trying to half pay attention to UML, but I am not that into it. Just too many tools to learn...
I took two classes in 1997 from UCSC extension that were aimed at getting us to use UML. I'm still trying to half pay attention to UML, but I am not that into it. Just too many tools to learn...
- Trac - I am getting pretty good at being a track user and I am better now with the wiki concept (I know, it's not that hard). Trac ROCKS!
- Eclipse and the Eclipse Python plugin. Eclipse is huge.
- ArgoUML looks interesting, especially if PyReverse generates the UML for me.
- and a million other little items!
04.23.2006 14:48
Annoying GIS data delivery systems
I am hitting the same frustration that I have been going through since about 1997. Why do people wrap data in silly web interfaces such that it is impossible to easily specify what data you have fetched and track it through a project? Today I am playing with local GIS data. First problem is that it is not that easy to find data sources. The city of Dover's web site says that they will take orders for maps. Great. Like they are going to give me gmt grids and Fledermaus scene files... I don't think so. I did find the GRANIT system at unh. I found a first dem to pull down, but what it does is not that fun. I get to download a GRANIT.zip for each item that I fetch. When I unzip that file, it unpacks to this:
-rwxrwxr-x 1044839 Jun 19 2000 dem169.dem -rwxrwxr-x 36523 Mar 6 13:21 dem169.htmlThose filenames are helpful (like I know what 169 is!), but what I prefer is to be able to pull these files with a sane URL so that I can pass along my notes in a useful form to others. I think along the lines of something like this:
#!/bin/bash echo "Fetch all raw data need for project X - ship tracking" echo "Region includes Portsmouth, Newington, Dover, Durham, Kittery, " echo "New Castle, and Rye areas" echo echo "DEM's" wget http://mygisdatasite.org/nh/portsmouth.dem wget http://mygisdatasite.org/nh/newington.dem wget http://mygisdatasite.org/nh/dover.dem wget http://mygisdatasite.org/nh/durham.dem wget http://mygisdatasite.org/nh/kittery.demBam! Someone could start following through how I assembled my data and get there much faster than my first time through. End of rant about data availability before I get carried away.
echo echo "Fetching completed Fledermaus scene file." echo "View with iview3d" wget http://mygisdatasite.org/nh/nh-ship-tracking.scene
04.23.2006 07:30
Debugging python programs in emacs
I was having trouble figuring out how
to get M-x pdb to start the debugger. I found a way around it. Add
this to where you would like to start debugging:
The big drawback of this is that you must restart the debugger each time and this will loose any debugger state that you want to keep between runs (like break points).
import pdb
pdb.set_trace()
Then start pdb in emacs like this. First do M-x pdb. When it says:
Run pdb (like this): pdbReplace pdb with your program.
Run pdb (like this): ./myprogram.py --foo -barIt will then drop into the pdb debugger when you get to the set_trace call and act like pdb, but emacs will follow along in the other view so you do not have to type list all the time.
The big drawback of this is that you must restart the debugger each time and this will loose any debugger state that you want to keep between runs (like break points).
04.21.2006 08:22
major speedups
I have been working on optimizing my
code. Profiling showed that I was calling the BitVector _getbit and
_setbit calls a million times each to handle just a 300 line log
file. That was just way too much. Here are my initial speed tests:
Then I used the profiler to identify the trouble spots. These mostly turned out to be abuses of calling the BitVector class too often and in very bad ways. I started with lazy evaluation at my top level class. This let me discard uninteresting messages by only decoding the first 6 bits. Then I did my translations to bitvectors with a lookup table so that I have 64 BitVectors ready to go. Finally, I changed the assembly of the large converted bitvector from a "bv += partialBV" loop to preallocating one large BitVector and just assigning in the partialBV in to the right place one bit at a time.
There is still more optimization possible down at level of my handler that pulls apart the bits to create the usable message, but I think the gains will be much smaller.
G4 1.5GHz laptop: 0300 11.10 real 10.18 user 0.28 sys 5000 137.85 real 131.15 user 0.97 sysAfter optimization, here are the new numbers:
4xG5 2.5 GHz: 0300 7.41 real 7.18 user 0.22 sys 5000 92.57 real 92.09 user 0.28 sys
G4 1.5GHz laptop: 0300 2.39 real 1.93 user 0.27 sys 5000 20.41 real 17.77 user 0.51 sysHow did I get such a large speedup? For starters, my initial coding was done to be as clear as possible. I picked simple looking code over speed. Only once I knew the whole system was behaving correctly, then I started optimizing. That isn't to say that I was ignore speed. I tried to design such that it would be easy to come back for an optimization pass.
4xG5 2.5 GHz 0300 1.50 real 1.23 user 0.22 sys 5000 11.66 real 11.37 user 0.25 sys
With the profiler showing: 81K _setbit calls 77k _getbit calls
Then I used the profiler to identify the trouble spots. These mostly turned out to be abuses of calling the BitVector class too often and in very bad ways. I started with lazy evaluation at my top level class. This let me discard uninteresting messages by only decoding the first 6 bits. Then I did my translations to bitvectors with a lookup table so that I have 64 BitVectors ready to go. Finally, I changed the assembly of the large converted bitvector from a "bv += partialBV" loop to preallocating one large BitVector and just assigning in the partialBV in to the right place one bit at a time.
There is still more optimization possible down at level of my handler that pulls apart the bits to create the usable message, but I think the gains will be much smaller.
04.19.2006 08:57
python hotshot
I gave hotshot a try...
Looks like most of my time is spent in the BitVector _getbit and _setbit calls. Now I need to reduce the number of those calls.
In [1]: import hotshot, hotshot.stats, test.pystone
In [3]: stats = hotshot.stats.load("ais-log2gzx.profile")
In [4]: stats.strip_dirs()
In [5]: stats.sort_stats('time','calls')
In [6]: stats.print_stats(20)
330324 function calls (330249 primitive calls) in 2.546 CPU seconds
Ordered by: internal time, call count
List reduced from 190 to 20 due to restriction <20>
ncalls tottime percall cumtime percall filename:lineno(function)
132849 1.111 0.000 1.111 0.000 BitVector.py:641(_getbit)
137087 0.506 0.000 0.506 0.000 BitVector.py:626(_setbit)
2607 0.368 0.000 1.481 0.001 BitVector.py:702(__add__)
5576 0.230 0.000 0.755 0.000 BitVector.py:541(__init__)
87 0.022 0.000 0.029 0.000 decimal.py:1143(_divide)
8992 0.020 0.000 0.020 0.000 BitVector.py:599(lambda)
22 0.019 0.001 0.830 0.038 msg.py:177(getFields)
46 0.017 0.000 1.594 0.035 binary.py:191(ais6tobitvec)
599 0.015 0.000 0.022 0.000 ElementTree.py:1072(start)
10069 0.015 0.000 0.015 0.000 ElementTree.py:220(__getitem__)
420 0.014 0.000 0.027 0.000 BitVector.py:829(intValue)
1124 0.013 0.000 0.116 0.000 binary.py:19(setBitVectorSize)
474 0.013 0.000 0.670 0.001 BitVector.py:906(__getslice__)
991 0.012 0.000 0.012 0.000 msg.py:83(getType)
2 0.011 0.005 0.067 0.034 ElementTree.py:1241(feed)
495 0.010 0.000 0.017 0.000 msg.py:85(getScale)
466 0.009 0.000 0.013 0.000 msg.py:118(isCase)
1 0.009 0.009 0.017 0.017 ElementTree.py:1110(__init__)
423 0.009 0.000 0.012 0.000 msg.py:102(getDecode)
445 0.009 0.000 0.012 0.000 msg.py:107(getUnavailableRaw)
Looks like most of my time is spent in the BitVector _getbit and _setbit calls. Now I need to reduce the number of those calls.
04.19.2006 07:53
Python speed
http://wiki.python.org/moin/PythonSpeed/PerformanceTips
looks like a good place to start for speeding up my python
code.
04.19.2006 06:55
Python performance testing
Now comes the time when I need to
start understand who costs what in python. My log file parse runs
very slow. In working up this program, I was aiming to get
the API and behavior correct all-the-while knowing that I was
coding this the "slow" way. I have a good sense of costs in the
C/C++/Fortran worlds, but not yet in Python. This is my chance to
get to know it better. I have a lot of searches through an element
tree in this code that could be turned into much faster array or
hash lookups. array lookup tables would take a lot of the code from
O(n) to O(1) and that O(1) would be with a very small constant. To
kick off the games, here is a graph of log files with increasing
number of log entries.
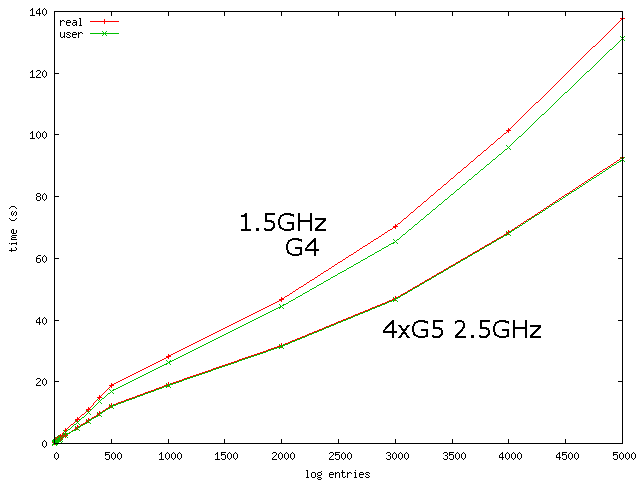
There are some interesting features to note. First, here is the results from time for the 5000 line log file:
Note that I am NOT doing any parallel processing in this python script. I would expect that the 4xG5 would be at least 2 times faster than the G4 laptop. The laptop has a slower memory bus which should really cause problems. Not seeing such slowdown implies that most of this python program is staying in cache on the CPU. This is not too surprising since all of the data structures are pretty small. Looking at the time spent on system calls, it is plain to see that the 4xG5 machine is generally much faster than the G4 almost by a factor of 4 when dealing with OS level calls. Another thing to note with these tests is that there is hardly any effort spent on disk IO. The largest log file is 211KB.
Finally, it is interesting no note that there is a knee in the graph at around 500 lines. I believe that this comes from the number of time stamps in the log file. Time stamps should take much less effort to process.
There are some interesting features to note. First, here is the results from time for the 5000 line log file:
1xG4 1.5GHz 137.85 real 131.15 user 0.97 sys 4xG5 2.5GHz 92.57 real 92.09 user 0.28 sys
Note that I am NOT doing any parallel processing in this python script. I would expect that the 4xG5 would be at least 2 times faster than the G4 laptop. The laptop has a slower memory bus which should really cause problems. Not seeing such slowdown implies that most of this python program is staying in cache on the CPU. This is not too surprising since all of the data structures are pretty small. Looking at the time spent on system calls, it is plain to see that the 4xG5 machine is generally much faster than the G4 almost by a factor of 4 when dealing with OS level calls. Another thing to note with these tests is that there is hardly any effort spent on disk IO. The largest log file is 211KB.
Finally, it is interesting no note that there is a knee in the graph at around 500 lines. I believe that this comes from the number of time stamps in the log file. Time stamps should take much less effort to process.
Log File Percent Length NumStamps Time Stamps 0001 0 0 0002 1 0.5 0003 1 0.333 0004 2 0.5 0005 2 0.4 0010 5 0.5 0020 10 0.5 0030 15 0.5 0040 20 0.5 0050 25 0.5 0100 50 0.5 0200 100 0.5 0300 150 0.5 0400 200 0.5 0500 250 0.5 Change in slope 1000 596 0.596 starts here 2000 1300 0.65 3000 1960 0.653 4000 2491 0.623 5000 2991 0.598
04.18.2006 05:28
New UNH coastal lab
Groups monitor UNH plan
for Odiorne lab
... Paul Chamberlin, the university interim assistant vice president for facilities, said the lab was originally going to be built near the New Castle Coast Guard Station, but neighboring historic structures prohibited it.Now I am confused, since several of us have been counting on that lab going in New Castle.
"There were also some issues raised by New Castle," namely the size of the structure and increased traffic the lab wouldâÄôve brought, Chamberlin said. "A few folks were very vocal with their concerns."
04.17.2006 18:51
epydoc - new version
epydoc 3.0alpha2 is out.
It looks like Ed fixed up the couple bugs that I ran into. I
checked it into fink (and I fixed the source location typo... sorry
about that).
04.16.2006 11:15
Calendar Server?
OpenExchange
may be that calendar system that I have been wanted. Or maybe not.
Now, can it integrate with trac?
04.16.2006 08:38
Porting to 64 bit machines
The first time I used a 64-bit
machine was back in the early 90's, but we as a community are still
trying to get there. I hardly used the 64 bit libraries of the SGI,
but now with 8 GB of RAM on one of my machines and problems that
really need that RAM, I need to get back into the 64-bit
game.
Porting Linux applications to 64-bit systems [IBM DeveloperWorks]
Porting Linux applications to 64-bit systems [IBM DeveloperWorks]
04.15.2006 08:24
lxml
lxml looks like an interesting
python interface to XML. Of special interest is support of XML
Schemas and Relax NG. It is a superset of ElementTree which means
that I should be able to switch to it without much hassle.
04.13.2006 11:23
Nationwide Automatic Identification System (NAIS)
Check out this Coast Guard website on
the National Automatic
Identification System (NAIS). Not much information yet and they
have some bugs with their JavaScript menus. Hopefully, they will be
adding more info soon.
04.13.2006 09:41
MapGuide
MapGuide looks pretty interesting
and is available under the LGPL license.
MapGuide Open Source is a web-based platform that enables users to quickly develop and deploy web mapping applications and geospatial web services.
MapGuide features an interactive viewer that includes support for feature selection, property inspection, map tips, and operations such as buffer, select within, and measure. MapGuide includes an XML database for storing and managing content, and supports most popular geospatial file formats, databases, and standards. The MapGuide platform can be deployed on Linux or Microsoft Windows, supports Apache and IIS web servers, and offers extensive PHP, .NET, Java, and JavaScript APIs for application development.
MapGuide Open Source is free, open source software licensed under the LGPL.
04.13.2006 09:35
global view of ship locations
Here is another project that I need
to tap into...
From Mapping Ship Locations
sailwx.info which uses NOAA's VOS: WMO Voluntary Observing Ships
Now I need a python interface to this data!
From Mapping Ship Locations
sailwx.info which uses NOAA's VOS: WMO Voluntary Observing Ships
Now I need a python interface to this data!
04.13.2006 08:15
type coercion in python
Today's python problem is comparing
values pulled out of XML fields. I pull out a field and run a
translator on it which gives me a float, Decimal, integer, or
string. Then I pull from another location a value that I want to
compare to the translated value. The trouble is that this second
value is always encoded in a string. I want to do the comparison
with a minimum of hassle, so I want to coerce the second value to
the type of the first. Confused yet? Here is the python code that
states the problem and shows the solution.
#!/usr/bin/env python # a=1 b='1' # assert (a!=b) assert (a== (type(a))(b) ) assert ( (type(b))(a)==b) # print (type(a))(b), type((type(a))(b)) print (type(b))(a), type((type(b))(a))When running this code, here is what I get:
./t.py 1 <type 'int'> 1 <type 'str'>Now that I see the solution to this problem, I don't know why it took me so long to figure it out. Perhaps because I have been a c programmer for almost 20 years. Being able to do this kind of thing makes like so much easier in python. I am sure I could do something clever in C or C++, but it would be so much more work.
04.12.2006 18:16
Suns XML modeling tools
Sun
opens modeling tools
Tools for UML, XML and service orchestrated architectures (SOAs) will become the latest features in Sun Microsystems Java Studio Enterprise suite to be open sourced. ...What exactly this is, I am not sure. The whole Java world seems a bit strange to me and I am not totally sure how to get and install install Java tools. Time to look at Eclipse again.
04.12.2006 07:54
pysqlite2-py24 in fink
I have stopped putting python 2.3 in
my python based packages. I figure less clutter for fink and few
maintence issues. The one drawback is that Mac OSX still has python
2.3 and no python 2.4. (Grr)
The announcement for this morning is that pysqlite2-py24 is now in fink 10.4-transitional/unstable. Trac users be warned. If you install this and your database is in sqlite2 format with pysqlite, when you restart trac it will bomb out. Here is how to upgrade your database:
The announcement for this morning is that pysqlite2-py24 is now in fink 10.4-transitional/unstable. Trac users be warned. If you install this and your database is in sqlite2 format with pysqlite, when you restart trac it will bomb out. Here is how to upgrade your database:
$ mv trac.db trac2.db $ sqlite trac2.db .dump | sqlite3 trac.dbWhich comes from http://projects.edgewall.com/trac/wiki/PySqlite
04.11.2006 22:02
MMI - Marine Metadata Interoperability
http://marinemetadata.org/ - Looks
interesting, but I have not dug into it yet.
04.11.2006 21:53
SensorML
Draft spec that Myche pointed me
to:
http://www.opengeospatial.org/specs/?page=requests&request=rfpc31
OGC Request 31: OpenGIS Sensor Model Language (SensorML): Request for Public Comments
http://www.opengeospatial.org/specs/?page=requests&request=rfpc31
OGC Request 31: OpenGIS Sensor Model Language (SensorML): Request for Public Comments
04.11.2006 18:59
Little OpenInventor Visualization
Here is a quick and dirty
OpenInventor file to view a sequence of images. Dirty is the key
word. Everything is hard coded.
#!/usr/bin/env python
print "#Inventor V2.0 ascii"
import glob
files = glob.glob('*.png')
offset = -500
for file in files:
offset += 100
print '''Separator {'''
if abs(offset)>50:
print ''' Material {transparency 0.8}'''
print '''
Translation {translation 0 '''+str(offset)+''' 0 }
Coordinate3 { point [ 0. 0. 0.0, 340 0.0 0.0,
0. 0. -200, 340 0.0 -200 ] }
BaseColor { rgb [ 0.5 0.5 0.5 ] }
Texture2 { filename "'''+file+'''" model DECAL }
TextureCoordinate2 { point [
0.0 1.0,
1.0 1.0,
0.0 0.0,
1.0 0.0,
] }
IndexedFaceSet { coordIndex [ 0, 1, 2, -1,
1, 3, 2, -1 ]}
IndexedLineSet { coordIndex [ 0, 1, 3, 2, 0 ] }
}'''
04.11.2006 17:17
USB gadgets
Just saw a little phidgets.com USB board. Turns out
the support Mac OSX and Linux. Like I need more projects, but looks
cool and reasonably cheap.
04.11.2006 13:45
python eval
Python's eval function is pretty
handy...
from math import *
value = 50
eval ('4.733*sqrt(value)')
33.467363953559293
04.11.2006 09:31
Virtual Globes Science Conference
Too many interesting things, not
enough time.
Conference Announcement Virtual Globes Scientific Users 10-12 July 2006 Boulder, Colorado
Registration Deadline: Friday, 9 June 2006
Further details on the conference, registration, and venue are available at: http://www.earthslot.org/vgconference/registration.php
The first annual Virtual Globes Scientific Users conference will be held 10-12 July 2006 in Boulder, Colorado. The intended goal of this conference is to assess the state-of-the-art in the use of online Virtual Globes (VGs) in support of earth sciences.
Earth sciences here should be interpreted broadly as including any aspect of the earth system, whether the focus is on land, oceans, or atmosphere or on physical, chemical, or biological processes. Virtual Globes in this context include any online tool which allows the user free-access to see a spinning globe at space level and interactively fly down to surface level with 3D perspective (such tools currently include Google Earth, World Wind, EarthSLOT, GeoFusion, and others). VGs are quickly becoming the new paradigm in earth science, earth science education and outreach, earth science logistics, and earth science data access.
This conference will address questions such as: - How are these tools currently being used in earth sciences? - How do they work? - How have they changed earth sciences? - What needs of earth sciences are currently not being met by the existing tools? - What should we expect for the future and what role should we play in it?
Organizers are interested in not just seeing final products, but also the tips, tricks, and traps that go into building such applications, as well as higher-level perspectives on how these tools may shape the future. As such, they hope to bring together earth scientists, educators, and related individuals who are currently using or planning to use VGs to support their work, with the intent of facilitating the formation of a community that can serve as a nucleus for support, discussion, promotion, and enhancement of use of VGs in the earth sciences. Part of this community-building effort will be a compilation of applications, websites, tutorials, etc., that can serve as a resource for future developments or earth-science events, such as the upcoming International Polar Year.
The conference will consist of 15-minute presentations, an interactive poster/laptop session, and several invited plenary talks. The presentations can cover any aspects of how VGs are being used to support earth scientists, educators, logisticians, data archivists, program managers, or the public. Internet will be available for presentations. Those presenting in the interactive session can either hang posters or use their wireless-enabled laptops. Several invited talks by VG software developers are also planned.
Space is limited, so registration is required, even for those not presenting. The registration deadline is Friday, 9 June 2006. Attendees are responsible for their own travel, lodging, and meal expenses.
Further details on the conference, registration, and venue are available at: http://www.earthslot.org/vgconference/registration.php
04.11.2006 09:16
wxOptParse
I just did a first pass at packaging
wxOptParse. I have GLib poll issues, but otherwise it seems to
work.
GLib-WARNING **: poll(2) failed due to: Invalid argument.http://schwehr.org/software/fink/wxoptparse-py.info
04.10.2006 19:52
quickstart trac
I am working on what happens with
trac when the pysqlite2 db driver is added after initial startup.
Here is my setup on Mac OSX 10.4.x:
cd ~/Desktop
mkdir trac
cd trac
mkdir svnroot
cd svnroot
svnadmin create `pwd`
cd ..
trac-admin ${HOME}/Desktop/trac/tracfoo initenv
Defaults for all except:
Path to repository > YOURHOMEDIR/Desktop/trac/svnroot
tracd --port 8000 /Users/schwehr/Desktop/trac/tracfoo
open http://localhost:8000/tracfoo
Now to install the pysqlite driver:
fink install pysqlite2-py24 tracd --port 8000 /Users/schwehr/Desktop/trac/tracfoo &
open http://localhost:8000/tracfoo
Available Projects * tracfoo: Error (file is encrypted or is not a database)
04.10.2006 15:59
DOD meta data clearing house
http://metadata.dod.mil/
Welcome to the DoD Metadata Registry and Clearinghouse!
The DoD Metadata Registry and Clearinghouse provides software developers access to data technologies to support DoD mission applications. Through the Metadata Registry and Clearinghouse, software developers can access registered XML data and metadata components, COE database segments, and reference data tables and related metadata information such as country codes and U.S. state codes. These data technologies increase the DoD's core capabilities by integrating common data, packaging database servers, implementing transformation media and using Enterprise data services built from "plug-and-play" components and data access components.
04.10.2006 14:13
New Methods Being Used to Support AIS Data Sharing
New Methods Being Used to Support AIS Data Sharing
In an effort to better share information amongst organizations that produce or consume data to enable maritime domain awareness (MDA), RDC is supporting the development of the MDA Data Sharing Community of Interest (DS COI). Immediate efforts are focused on the development of a common data vocabulary and a pilot project for AIS information. The goal of the pilot project is to access AIS information from more than one producer and make that information available to more than one data consumer. The pilot team, led by Navy SPAWAR PEO-C4I and Space ISR (PMW-180), intends to use the net-centric infrastructure developed by the DOD Defense Information Systems Agency to connect Navy (SPAWAR) and RDC AIS information and make it available in XML format. Data consumer applications with access rights could then discover and connect to the data producers enabling this new approach to share information across DOD and DHS.
Project: Automatic Identification System Research and Development (2410.5)
RDC POC: Mr. Jay Spalding
04.10.2006 07:52
svn keyword properties
In order to use keywork substitution
in svn like what is available by default in CVS (which is not a
good thing to have automatically turned on), you need to use a svn
command like this:
svn propset svn:keywords "Revision Date" myfile.py svn commit -m "added keywords" myfile.pyWhich ended up doing something like this:
__version__ = '$Revision: 347 $'.split()[1] __date__ = '$Date: 2006-03-31 10:00:27 -0500 (Fri, 31 Mar 2006) $'.split()[1] __author__ = 'Kurt Schwehr'Too bad epydoc currently does not understand that I want my __version__ to be just 347.
04.10.2006 06:36
relax ng
I have yet to see a good discussion
as to which Schema language is the best. I wrote my first (and only
so far) schema in XML Schema. The RELAX NG ("relaxing") home page
is http://relaxng.org/
The list of software tools on that site is intriguing. Sun has relaxngconverter to convert from other schema languages to RELAX NG. libxml2 is supposed to know about Relax NG and there is the Jing validator. Finally, isntancetoschema (i2s) makes Relax NG schemas from XML documents. That would have been great for my first project! Is there something like that for XML Schema?
And finally, the main reason I should pay attention to Relax NG is that there is a schema for XML Schema... xmlsschema.rng
Now how do I use libxml2 to validate my schema with a schema? Ah, finally found http://www.w3.org/TR/2001/REC-xmlschema-1-20010502/#normative-schemaSchema which is the schema for XML schemas. Doh! Where exactly is datatypes.xsd that is required for the normative schema?
The list of software tools on that site is intriguing. Sun has relaxngconverter to convert from other schema languages to RELAX NG. libxml2 is supposed to know about Relax NG and there is the Jing validator. Finally, isntancetoschema (i2s) makes Relax NG schemas from XML documents. That would have been great for my first project! Is there something like that for XML Schema?
And finally, the main reason I should pay attention to Relax NG is that there is a schema for XML Schema... xmlsschema.rng
Now how do I use libxml2 to validate my schema with a schema? Ah, finally found http://www.w3.org/TR/2001/REC-xmlschema-1-20010502/#normative-schemaSchema which is the schema for XML schemas. Doh! Where exactly is datatypes.xsd that is required for the normative schema?
04.10.2006 06:18
including xml within xml
Val showed me how to do this last
week, but I stumbled across a good web page description of
including one xml file in another.
<?xml version="1.0"?>
<!DOCTYPE novel SYSTEM "/dtd/novel.dtd" [
<!ENTITY chap1 SYSTEM "mydocs/chapter1.xml">
<!ENTITY chap2 SYSTEM "mydocs/chapter2.xml">
<!ENTITY chap3 SYSTEM "mydocs/chapter3.xml">
<!ENTITY chap4 SYSTEM "mydocs/chapter4.xml">
<!ENTITY chap5 SYSTEM "mydocs/chapter5.xml">
]>
<novel>
<header>
...blah blah...
</header>
&chap1;
&chap2;
&chap3;
&chap4;
&chap5;
</novel>
from http://xml.silmaril.ie/authors/includes/.04.09.2006 08:12
simple enum
I am not sure this is exactly how it
should be done, but here is a pretty stripped down example of xml
enums.
<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="SONG" type="songType"/>With the above xsd schema file, this validates:
<xsd:simpleType name="oligopolyMember"> <xsd:restriction base="xsd:string"> <xsd:enumeration value="Capitol Records, Inc."/> <xsd:enumeration value="BMG Music"/> </xsd:restriction> </xsd:simpleType> <xsd:complexType name="songType"> <xsd:sequence> <xsd:element name="PUBLISHER" type="oligopolyMember" minOccurs="0"/> </xsd:sequence> </xsd:complexType> </xsd:schema>
<?xml version="1.0"?> <SONG xmlns:xsi="http://www.w3.org/2001/XMLSchema"> <PUBLISHER>BMG Music</PUBLISHER> </SONG>and this fails to validate...
<?xml version="1.0"?> <SONG xmlns:xsi="http://www.w3.org/2001/XMLSchema"> <PUBLISHER>foo</PUBLISHER> </SONG>like so:
xmllint --schema enum.xsd enum.xmlI started with an example from this web page, but it was too complicated, so I stripped it down... http://www.cafeconleche.org/slides/xmlonelondon2001/schemas/38.html
enum.xml:3: element PUBLISHER: Schemas validity error : Element 'PUBLISHER': [facet 'enumeration'] The value 'foo' is not an element of the set {'Capitol Records, Inc.', 'BMG Music'}. enum.xml:3: element PUBLISHER: Schemas validity error : Element 'PUBLISHER': 'foo' is not a valid value of the atomic type 'oligopolyMember'. enum.xml fails to validate
04.09.2006 06:29
SIO on the Apple web page
There is a nice article on the Apple
Science web site about SIO. It includes pictures of Atul Nayak,
Debi Kilb, Graham Kent, and John Orcutt. It also looks like Bridget
Smith's thesis work in the first image.
Scripps Institution of Oceanography - Seeing the Big Picture [apple.com]

Scripps Institution of Oceanography - Seeing the Big Picture [apple.com]
04.08.2006 21:32
Subscribing to news groups
I haven't "subscribed" to a news
group for the first time in about 10 years. At Stanford, I
subscribed to the ir news group that mirrored and bridged the Sweet
Hall question/answer email. I learned a lot of my unix skills
there. Now with google groups, there is a little XML button at the
bottom of the page for each group. I subscribed to comp.lang.python
and comp.lang.xml. How long until I get overloaded and start nuking
feeds? Probably not long.
Flash backs to the days of when 36.x.x.x was all Stanford, afs rocked, and the "cool kids" hung out in the secret SGI workstation rooms. Nothing like an all nighter in the basement of the CS building. And no, I don't mean the Gates building.
Flash backs to the days of when 36.x.x.x was all Stanford, afs rocked, and the "cool kids" hung out in the secret SGI workstation rooms. Nothing like an all nighter in the basement of the CS building. And no, I don't mean the Gates building.
04.08.2006 07:09
National Geologic Map Database
I was all excited to find this web
page: NGMDB - the
national geologic map database. Then I discoved that there are no
maps in the area that I live and work. The overall US coverage is
very weak and it is sad to say that my GIS work will never make it
in there.
04.07.2006 09:53
VoidSpace python coding style
I don't totally agree with all of his
guidelines, but VoidSpace has his:
style guide
Also, PythonIdioms has things like:
Also, PythonIdioms has things like:
Wrong: for s in strings: result += s Right: result = ''.join(strings)
04.07.2006 09:39
SnowFlake GML viewer
SnowFlake has a free (?) GMLViewer
that includes Mac, Linux, and MS Windows support.
04.07.2006 08:13
using name rather than ref
Now that I have a base that I know
works, it is much easier to try things out. The first thing to try
is to switch from ref attributes that require a reference
definition in the document to named ones.
<?xml version='1.0' encoding='UTF-8'?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" blockDefault="#all"
elementFormDefault="qualified" xml:lang="EN"
version="Id: structures.xsd,v 1.2 2004/01/15 11:34:25 ht Exp ">
<xs:element name="ais">
<xs:complexType>
<xs:complexContent>
<xs:extension base="xs:anyType">
<xs:attribute name="version" type="xs:string"/>
<xs:attribute name="date" type="xs:string"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
</xs:element>
</xs:schema>
Where I removed these from the previous version:
<xs:attribute ref="version"/>
<xs:attribute ref="date"/>
<xs:attribute name="version" type="xs:string"/>
<xs:attribute name="date" type="xs:string"/>
04.07.2006 07:55
xml documentation
xml.com seems like a good place to start
reading in addition to the O'Rielly Learning XML book, the Visual
Quickstart XML book is a good companion (for me so far). However,
the Visual Quickstart is definitely not a stand-alone book for the
beginner. I need complete examples. Is there a tutorial out there
that talks about learning, building, and validating DTDs and
Schemas all at the same time?
http://www.oreilly.com/pub/topic/xml
For the Mac, OxygenXML looks pretty good.
I tried xmlNanny, but got tons of errors that I did not understand. Not much info in that tool. Maybe it is good for web pages?
http://www.oreilly.com/pub/topic/xml
For the Mac, OxygenXML looks pretty good.
I tried xmlNanny, but got tons of errors that I did not understand. Not much info in that tool. Maybe it is good for web pages?
04.07.2006 07:11
xsv works
I just got the xsv command line
program properly built and it now "works for me." You will need
ltxml.info, pyltxml-py.info, and xsv-py.info from http://schwehr.org/software/fink
fink install ltxml pyltxml-py24 xsv-py24 wget http://www.xml.com/2000/11/29/schemas/library1.xsd xsv library1.xsd
04.06.2006 15:04
ajax library
I was told today that the best/most
popular AJAX javascript library is prototype but there are also
libraries named RICO, DWR, JSON, and AFLAX. I really don't know
anything about writing AJAX type web applications at this
point.
04.06.2006 15:00
ltxml and xsv
I just created fink packages for
ltxml and xsv-py since there was talk about xsv being a good tool
for xsd schema validation. These are pretty rough.
04.06.2006 11:09
xml part 3 - attributes
Brian and I got a schema to work that
adds two attributes to to root level ais tag. It has been a tough
couple of hours trying to understand what is going on (which I am
pretty sure I still do not understand this). To start with, I have
a new Makefile validation rule:
validate:
xmllint ais.xsd
xmllint ais.xml
xmllint --schema ais.xsd ais.xml
xml val -e ais.xml
xml val -e ais.xsd
xml val -e --xsd ais.xsd ais.xml
Then the new xml that needs to be validated includes version and
date attributes.
<?xml version="1.0"?>
<ais xmlns:xsi="http://www.w3.org/2000/10/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="ais.xsd" version="1.0" date="2006-Apr-04">
</ais>
Here is the xsd schema that we came up with thanks to E. Castro's
book.
<?xml version='1.0' encoding='UTF-8'?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" blockDefault="#all"
elementFormDefault="qualified" xml:lang="EN"
version="Id: structures.xsd,v 1.2 2004/01/15 11:34:25 ht Exp ">
<xs:element name="ais">
<xs:complexType>
<xs:complexContent>
<xs:extension base="xs:anyType">
<xs:attribute ref="version"/>
<xs:attribute ref="date"/>
</xs:extension>
</xs:complexContent>
</xs:complexType>
</xs:element>
<xs:attribute name="version" type="xs:string"/>
<xs:attribute name="date" type="xs:string"/>
</xs:schema>
04.06.2006 11:07
Seacoast to get new aerial photos
Seacoast
towns to update aerial photos [Sea Coast Online]
04.06.2006 10:25
xml try number 2
ais.xsd
<?xml version='1.0' encoding='UTF-8'?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" blockDefault="#all"
elementFormDefault="qualified" xml:lang="EN"
version="Id: structures.xsd,v 1.2 2004/01/15 11:34:25 ht Exp ">
<xs:element name="ais">
</xs:element>
</xs:schema>
ais.xml
<?xml version="1.0"?> <ais xmlns:xsi="http://www.w3.org/2000/10/XMLSchema-instance" xsi:noNamespaceSchemaLocation="ais.xsd"> </ais>seems to validate okay with these two commands:
xmllint --schema ais.xsd ais.xml xml val -e --xsd ais.xsd ais.xml
04.05.2006 15:16
GML - Geography Markup Language
I just grabbed the GML zip with
schemas and a 600+ page pdf describing the language from
http://opengis.net/gml/. That
is a monster. But it has quite a few xsd files that should
hopefully make things easier to understand.
04.05.2006 14:08
simplest xsd schema example
In my quest to get this stuff figured
out, here is the simplest example that I can come up with that
validates. First the GNU Makefile:
validate:
xmllint ais.xsd
xmllint ais.xml
xml val -e --xsd ais.xsd ais.xml
html:
code2html -l html ais.xsd > ais.xsd.html
code2html -l html ais.xml > ais.xml.html
code2html Makefile > Makefile.html
clean:
rm *.html
I like the idea of validating with multiple tools. The more checks
the better and if there is an error, one program may have a more
comprehensible error message. Now the xsd schema. This is not much.
<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="ais"> </xsd:element> </xsd:schema>Finally, the xml document:
<?xml version="1.0"?> <ais> </ais>
04.05.2006 13:39
xml acryonym soup
I feel like I am lost in NASA documentation where I need a lookup table of acronyms to understand what I am reading about. What am I trying to do? I just want to create an xml schema that can validate a new xml fomatted config file that I am working on. How hard can that be? Well, I got lost for a couple hours. Then I found xmlstartlet.txt. What is so good about it? Just the existance of test cases that work from the command line... and it provides the input files.
xml val -s xsd/table.xsd xml/table.xmlI was trying to write a schema and all xmllint would tell me is that it thought my file was not a schema. Thanks.
For your viewing pleasure, here is the table example xsd (the schema to validate against) and a sample document. table.xsd:
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="xml">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="table">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="rec" maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="numField" type="xsd:int"/>
<xsd:element name="stringField" type="xsd:string"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:NMTOKEN" use="required"/>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
and table.xml
<?xml version="1.0"?>
<xml>
<table>
<rec id="1">
<numField>123</numField>
<stringField>String Value</stringField>
</rec>
<rec id="2">
<numField>346</numField>
<stringField>Text Value</stringField>
</rec>
<rec id="3">
<numField>-23</numField>
<stringField>stringValue</stringField>
</rec>
</table>
</xml>
Maybe now I can make some progress!
xmlstarlet looks like it does quite a bit of jobs with xml. I have a feeling that I will be using it a fair bit in the near future. Maybe I can make a few schemas for geozui if they do not already exist.
xsddoc might also be handy, but being that it is in java, I need to hold off a bit before packaging it. The output is nice.
04.04.2006 19:56
Open Source security strategy
Open Source
Security Testing Methodology Manual [osnew]
ISECOM is an open, collaborative, security research community established in January 2001. Recently, Pete Herzog, founder of ISECOM and creator of the OSSTMM, talked about the upcoming revision 3.0 of the Open Source Security Testing Methodology Manual. He discusses why we need a testing methodology, why use open source, the value of certifications, and plans for a new vulnerability scanner developed with a different approach than Nessus.
04.04.2006 14:47
10.4.6
Just a warning: The reboot process
for the 10.4.6 upgrade reboots twice. And it overall process took
about 7-8 minutes on my laptop.
uname -a Darwin my-computer 8.6.0 Darwin Kernel Version 8.6.0: Tue Mar 7 16:58:48 PST 2006; root:xnu-792.6.70.obj~1/RELEASE_PPC Power Macintosh powerpc
04.04.2006 09:28
elementtry 1st program
The first thing to try in elementtree
is to view the structure of an xml file. Yes, this is easier done
with a graphical tool, but this illustrates how to use elementtree.
First the code. This is a simple recursive decent of the children.
#!/usr/bin/env python import sys from elementtree.ElementTree import parseNow for something to parse:
def printEleTree(ele,indent=' '): if None==ele: return 0 c = ele.getchildren() count = 0 for child in c: count += 1 print indent+child.tag num = printEleTree(child,indent+' ') if num > 0: print indent+'end '+child.tag+' numchildren = '+str(num) return count
filename=sys.argv[1] tree = parse(filename) root=tree.getroot() print root.tag num = printEleTree(root) print 'end'+root.tag+' numchildren = '+str(num)
<?xml version="1.0" encoding="ISO8859-1" ?> <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note>Running the above code on the note.xml file looks like this:
./printxml.py note.xml note to from heading body endnote numchildren = 4How about some (slightly) more complicated xml...
<?xml version="1.0" encoding="ISO8859-1" ?>
<breakfast-menu>
<food>
<name>Belgian Waffles</name>
<price>$5.95</price>
<description>two of our famous Belgian Waffles with plenty of real maple syrup</description>
<calories>650</calories>
</food>
<food>
<name>Strawberry Belgian Waffles</name>
<price>$7.95</price>
<description>light Belgian waffles covered with strawberrys and whipped cream</description>
<calories>900</calories>
</food>
</breakfast-menu>
Which looks like this:
./printxml.py simple.xml
breakfast-menu
food
name
price
description
calories
end food numchildren = 4
food
name
price
description
calories
end food numchildren = 4
endbreakfast-menu numchildren = 2
04.04.2006 07:00
xml convert
Up until yesterday, I was pretty much
set in my ways of disliking xml. I've tried using xml in the past
and I have seen some projects that have a variety of xml issues. So
why would I intentionally use xml?
Yesterday was that tipping point for me. I am now addicted to XML. Not for everything, but for a project I am working now, the core will switch from python code (with a lot of dictionaries) to xml. Why did I switch? There was a culmination of a range of factors that have building over time. The first is that Roland and Matt built the geozui formats on xml. I have been working with those formats and watching Roland write xml handlers. Then I was talking with Capt Ben and Brian L. about how to layout a project. Brian offered a range of suggestions on how to refactor my initial prototype. Both Ben and Brian asked a lot of questions that mirrored my feeling about my draft API. It was pretty confusing. It works and is more straight forward that the generation before mostly because things like python make life easier than C/C++. Then Brian said, "Why aren't you doing this in ML?" He sketched a couple tags on the white board. Now being in a place with a bunch of developers who use xml, I saw how this would make my design so much simpler:
WX: very rainy
Yesterday was that tipping point for me. I am now addicted to XML. Not for everything, but for a project I am working now, the core will switch from python code (with a lot of dictionaries) to xml. Why did I switch? There was a culmination of a range of factors that have building over time. The first is that Roland and Matt built the geozui formats on xml. I have been working with those formats and watching Roland write xml handlers. Then I was talking with Capt Ben and Brian L. about how to layout a project. Brian offered a range of suggestions on how to refactor my initial prototype. Both Ben and Brian asked a lot of questions that mirrored my feeling about my draft API. It was pretty confusing. It works and is more straight forward that the generation before mostly because things like python make life easier than C/C++. Then Brian said, "Why aren't you doing this in ML?" He sketched a couple tags on the white board. Now being in a place with a bunch of developers who use xml, I saw how this would make my design so much simpler:
- Parsers can easily be written in any language that supports xml.
- Non programmers have a chance of updating the xml document that specifies the formats.
- It is possible to generate nice documentation of the formats directly from the xml document. The original spec is not very machine readable.
- Python has pyxml and elementtree which both handle reading and writing xml files. Elementtree is supposed to become part of the Python Standard Library. And Elementtree is not to bad to learn.
- Other people using the same technology in the local neighborhood makes using that tech much easier.
WX: very rainy
04.04.2006 06:02
OSX Repair Permissions
Just yesterday, I got the latest UNH
computing group news letter. In that letter they said that it is
critical to run Repair Permissions BEFORE and AFTER any update to a
Mac. So I have found a "them" from this article... Daring
Fireball - Repair Permissions
We are told to repair permissions before and after each update by whom? Certainly not by Apple. Perhaps Cruse means "them", the same "them" who, in the classic Mac OS era, recommended zapping your PRAM every time you need to reboot your Mac after the system was wedged by a crashed app.For the record, since my very first Mac in 2001, I have never once run repair permissions. fsck: yes. repair permissions: no.
04.03.2006 07:30
sf.net cvs still down
Doh! The sourceforge.net cvs server
is still down after trouble on March 30th.
(2006-03-31 07:00:01 - Project CVS Service ) On 2006-03-30 the developer CVS server had a hardware issue that required us to take the service offline. We are actively working on this problem and hope to have it back up soon. There is not a current estimate for the duration of this outage, but when we get one, it will be posted on the site status page (this page). We currently expect this outage to last 48 hours, at minimum.
04.02.2006 12:01
decoding a ship name
I took two messages and combined them
into one long one like this:
!AIVDM,2,1,1,A,58Lh=j02;?TTQ<=@000<P4hu@Pu8r0p58DD00016A0L7D50m0Hl3lU4k,0*3B !AIVDM,2,2,1,A,@00000000000000,2*55'Becomes:
!AIVDM,1,1,,A,58Lh=j02;?TTQ<=@000<P4hu@Pu8r0p58DD00016A0L7D50m0Hl3lU4k@00000000000000,0*49Then I converted this NMEA string from the message 5 format and found that the strings contain:
HSCT CHALOTHORN NAREE 4C4%D3PWhen I look at the stern of the ship, I can see that the name is correct!
04.02.2006 09:23
Schooltool's calendar
In the quest for calendaring... saw
someone talking about this on #python
http://www.schooltool.org/products/schooltool-calendar. Of course if this doesn't integrate with our authentication system, then it isn't much use.
http://www.schooltool.org/products/schooltool-calendar. Of course if this doesn't integrate with our authentication system, then it isn't much use.
04.02.2006 08:27
epydoc 3.0a bug
Just ran into what I consider a bug
in epydoc. In my scripts subdirectory for my current project, I
have foo-job1, foo-job2, foo-bar which are all python programs that
provide a command line interface (CLI) to this package. When I try
to run epydoc on foo-bar, it completely fails, I also get a
foo-barc file from the compilation. I tried making a link to
foo-bar.py, but that also fails. What I have to do for epydoc (and
i think this is more a python general issue) is to make a link from
foo-bar to foo_bar.py, but then all the documentation is pretty
confused.
Maybe the solution is for epydoc to rename to file on the file, generate the documentation, and then translate everything inside the docs to match the original?
My other major interest with epydoc (and I think I am going to have to start hacking epydoc) is to generate html listings of the source with all the documentation stripped out. With all the documentation embedded in the code, it can get hard to follow. If I can have two browser windows open at the same time while editing the code, I would then be able to see just the clean html documentation and a clean and compact bit of code. Some of my python files are 3/4 documentation.
I posted a documentation question on comp.lang.python, but only got one email saying to look at numarray for an example. The nntp (remember that? not ntp) thread via google groups: packaging question - documentation
Maybe the solution is for epydoc to rename to file on the file, generate the documentation, and then translate everything inside the docs to match the original?
My other major interest with epydoc (and I think I am going to have to start hacking epydoc) is to generate html listings of the source with all the documentation stripped out. With all the documentation embedded in the code, it can get hard to follow. If I can have two browser windows open at the same time while editing the code, I would then be able to see just the clean html documentation and a clean and compact bit of code. Some of my python files are 3/4 documentation.
I posted a documentation question on comp.lang.python, but only got one email saying to look at numarray for an example. The nntp (remember that? not ntp) thread via google groups: packaging question - documentation
04.01.2006 17:12
Realtime weather data
http://airmap.unh.edu/data/aq.html
There is a station down at Pierce Island which has this URL on the side http://www.des.state.nh.us/
There is a station down at Pierce Island which has this URL on the side http://www.des.state.nh.us/